
文字コードの落とし穴を回避!UTF-8とShift_JIS(CP932)の正しい付き合い方
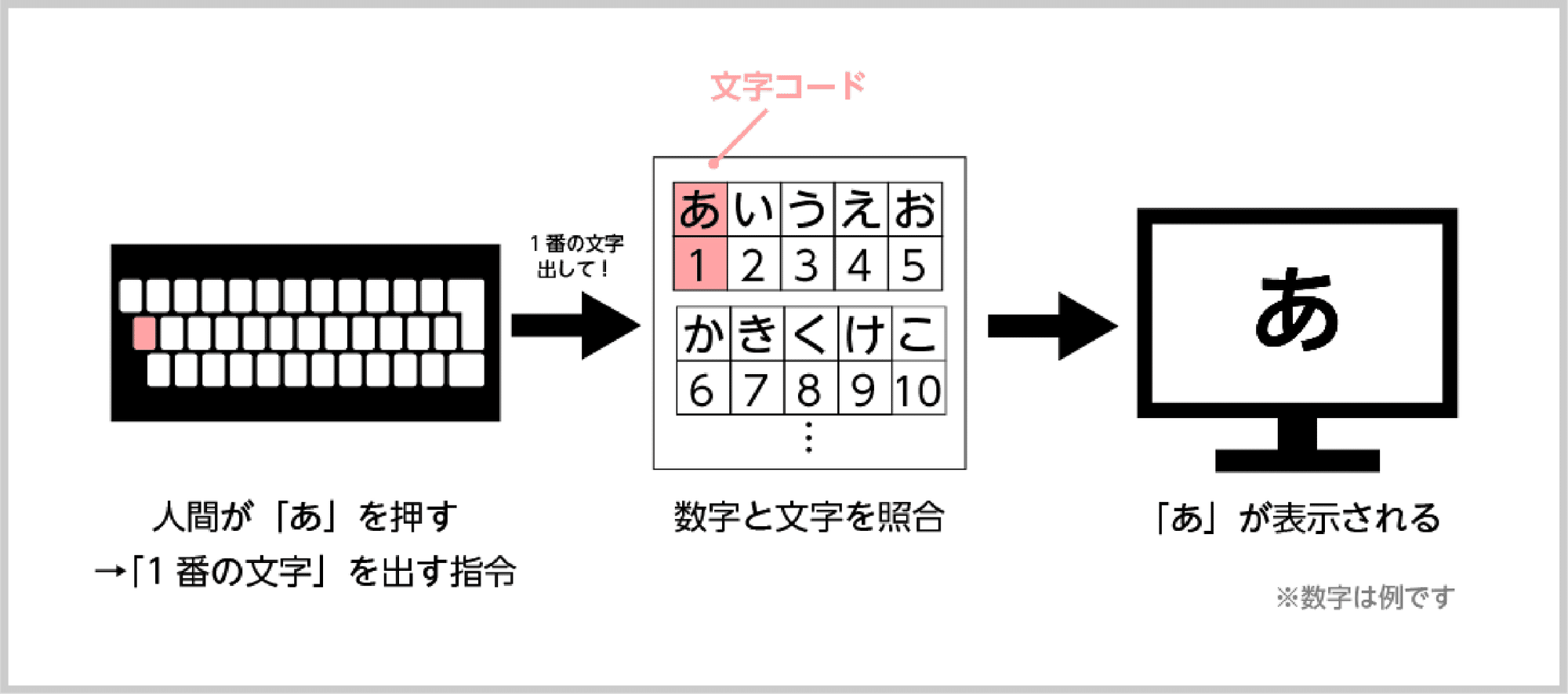
日本語の文章を扱っていて「文字化け」に遭遇した経験はありませんか?メールやテキストファイルを開いたときに「縺ゅ≠」や「���」のような、意味不明な文字列が現れる現象です。これは文字コード(エンコーディング)の不一致が原因で起こります。コンピュータは文字を数値の羅列(バイト列)として記憶しており、その数値をどの文字に対応させるかというルールブック(文字コード)に従って画面に表示します。文字化けは、あるルールブックで書かれた文章を、違うルールブックで読もうとしたときに発生する「翻訳ミス」のようなものなのです。
例えば、現在主流の「UTF-8」というルールで保存された日本語テキストを、古いWindowsで標準的だった「Shift_JIS」というルールで読み取ってしまうと、文字化けが起こります。特に「縺」「繧」「繝」といった、見慣れない糸偏の漢字がずらっと並ぶ文字化けは、UTF-8のデータをShift_JISとして読み取ったときの典型的なパターンです。 逆に、Shift_JISのデータをUTF-8で読み取ろうとすると「????」のように表示されることが多くあります。 このように、文字化けのパターンから原因を推測することも可能です。
この記事では、ビジネスパーソンの方でも文字化けの謎を解き明かせるよう、専門用語を避けつつ、UTF-8とShift_JISの違いから実践的な対策までを丁寧に解説します。
UTF-8とShift_JIS(CP932)の違いとは?
なぜUTF-8とShift_JISを読み間違えると文字化けが起こるのでしょうか?それは、二つのルールブックの仕組みが根本的に異なるからです。それぞれの特徴を比較してみましょう。

UTF-8:世界標準の文字コード
UTF-8(ユーティーエフエイト)は、世界中のほぼ全ての言語の文字を一つのルールで表現できる、非常に強力な文字コードです。 アルファベット、ひらがな、漢字、絵文字まで、あらゆる文字を扱えるため、現在のウェブサイト制作では事実上の世界標準となっています。 文字の種類によって、1文字を表現するのに使うデータ量(バイト数)が変わる「可変長」という特徴があります。 例えば、半角のアルファベットは1バイト、日本語のひらがなや多くの漢字は3バイトで表現されます。
- 長所:世界中のあらゆる言語を統一的に扱えるため、国際的なデータのやり取りに強い。
- 短所:日本語だけの文章の場合、後述するShift_JISよりもデータ量が少し大きくなることがある。
Shift_JIS(CP932):日本語環境の“元”標準
Shift_JIS(シフトジス)は、主に日本語を表現するために作られた文字コードです。 かつてのパソコン通信や初期のWindowsで標準的に使われていたため、古いシステムや一部の業務用ソフトウェアでは今でも現役です。 Shift_JISは、半角アルファベットを1バイト、日本語の全角文字を2バイトで表現します。
ちなみに、Windowsで「Shift_JIS」として扱われるものは、厳密には「CP932(コードページ932)」という、Microsoftが拡張したバージョンであることがほとんどです。 CP932は、Shift_JISでは表現できない丸付き数字(①②)や特殊な記号(㈱など)を含んでおり、より実用的になっています。 この記事では、これらをまとめて「Shift_JIS系」と呼びます。
- 長所:古い日本のシステムとの互換性が高い。日本語のみのテキストではデータ量がUTF-8より小さくなる場合がある。
- 短所:日本語以外の言語(特に絵文字や特殊な記号)は基本的に扱えず、文字化けの原因になりやすい。
比較表:UTF-8 vs Shift_JIS(CP932)
| 項目 | UTF-8 | Shift_JIS(CP932) |
|---|---|---|
| 対応文字 | 世界中のほぼ全ての言語・記号 | 日本語と一部の記号が中心 |
| データ量(1文字あたり) | 1~4バイト(可変) | 1バイト(半角)または2バイト(全角) |
| 主な利用シーン | 現在のWeb、新しいシステム全般 | 古いWindowsアプリ、一部の業務用システム |
| 推奨度 | ◎(こちらを使いましょう) | △(互換性のためにやむを得ない場合のみ) |
結論として、これから新しく作成するファイルやデータは、原則としてUTF-8を選ぶのが最も安全で確実です。
実践!文字化けを防ぐ具体的な方法
文字化けを防ぐための基本原則は、「保存する側」と「開く側」で文字コードを一致させることです。ここでは、具体的なツールでの設定方法を見ていきましょう。
テキストエディタでの設定
Windows付属の「メモ帳」や、その他のテキストエディタでは、ファイルを保存する際に文字コードを指定できます。保存ダイアログの下部にある「エンコード」や「文字コード」といった項目を確認しましょう。
- ANSI: 日本語版Windowsでは、これがShift_JIS(CP932)を指します。
- UTF-8: 世界標準のUTF-8です。特別な理由がなければこちらを選びましょう。
もしファイルを開いた時点で文字化けしていた場合、多くのエディタには文字コードを指定して開き直す機能があります。エンコード設定を切り替えて、正しく表示されるものを探してみましょう。
プログラミング(Python)での注意点
プログラミングでファイルを扱う際も、文字コードの指定は非常に重要です。ここでは、人気のプログラミング言語Pythonを例に見てみましょう。
Pythonでテキストファイルを読み書きする際は、open()という命令を使いますが、その際にencodingというパラメータで文字コードを明示的に指定するのが鉄則です。
# UTF-8で書かれたファイルを正しく読み込む例
with open('utf8_data.txt', 'r', encoding='utf-8') as f:
text = f.read()
print(text)
# Shift_JISで書かれたファイルを読み込む必要がある場合の例
with open('sjis_data.txt', 'r', encoding='cp932') as f:
text = f.read()
print(text)
このように、扱うファイルの文字コードを正しく指定することで、プログラム内での文字化けを防ぐことができます。 特にWindows環境では、encodingを省略するとShift_JIS(CP932)で読み込もうとするため、UTF-8のファイルを開くとエラーになることが多く注意が必要です。
上級編:BOM(ボム)って何?
文字コードの話で時々登場するのが「BOM(ボム)」という存在です。これも文字化けの意外な原因になることがあるので、少しだけ触れておきましょう。

BOM(Byte Order Mark)とは、テキストファイルの先頭に付加されることがある「このファイルはUTF-8ですよ」という目に見えない“しるし”のようなものです。 このしるしがあるファイルを「BOM付きUTF-8」と呼びます。
BOMがあると便利な場面もあります。例えば、ExcelでCSVファイルを開くときです。Excelは、BOMが付いていないUTF-8のCSVファイルを開くと、Shift_JISだと勘違いして文字化けを起こすことがあります。 しかし、BOM付きのUTF-8であれば、Excelは「これはUTF-8だ!」と正しく認識し、文字化けを防いでくれます。
一方で、BOMが問題を引き起こすこともあります。一部のプログラムや古いシステムはBOMを認識できず、ファイルの先頭に謎の文字(など)が表示されたり、プログラムが誤作動したりする原因になります。 そのため、Web開発の世界では、HTMLファイルなどを「BOM無しUTF-8」で保存するのが一般的です。
テキストエディタによっては、保存時に「UTF-8」と「UTF-8(BOM付き)」を選べる場合があります。 基本的には「BOM無し」を選び、Excelなど特定の相手とデータをやり取りする際に問題が起きたら「BOM付き」を試す、という使い分けをすると良いでしょう。
応用編:Pythonのエラー処理
もしプログラムで文字コードが不明なファイルを扱わなければならない場合、Pythonのopen()命令にはerrorsという便利なパラメータがあります。 これは、文字コードの変換エラーが起きたときにどう振る舞うかを指定できるものです。
errors='ignore': エラーになった文字を無視して処理を続行します。その部分のデータは欠落します。errors='replace': エラーになった文字を「?」などの代替文字に置き換えて処理を続行します。
# UTF-8として読めない文字があっても、無視して読み込む例
with open('unknown_encoding.txt', 'r', encoding='utf-8', errors='ignore') as f:
data = f.read()
print(data)
これはあくまで応急処置ですが、「処理を止めずに、読める部分だけでも読み進めたい」といった場合に有効なテクニックです。 ただし、データが失われる可能性がある点には注意が必要です。
まとめ:正しい知識で文字化けを恐れない
今回は、文字化けの主な原因であるUTF-8とShift_JISの違いと、その対策について解説しました。
- 文字化けの原因は「文字コードの不一致」:書いたルールと読むルールが違うと文字は化ける。
- 基本は「UTF-8」を使う:新しく作るデータは、国際標準であるUTF-8を選ぶのが安全。
- 相手の環境に合わせる:古いシステムやExcelと連携する場合は、Shift_JISや「BOM付きUTF-8」が必要な場面もある。
- ツールで正しく指定する:ファイルを保存・読み込みする際は、必ず文字コードを意識して指定する習慣をつける。
文字コードは一見とっつきにくいテーマですが、基本的なルールさえ押さえれば、文字化けのトラブルは大幅に減らせます。この記事が、皆さんの快適なデジタルライフの一助となれば幸いです。
“`
Sources
help
note.com
dailyportalz.jp
profuture.co.jp
tcd-theme.com
creativevillage.ne.jp
ameblo.jp
codecamp.jp
homepage-tukuri.com
hatenablog.com
python-izm.com
qiita.com
itmedia.co.jp
digibeatrix.com
qiita.com
zenn.dev
wikipedia.org
qiita.com
bureau-mikami.jp
qiita.com
learningbox.online
popinsight.jp
learnbyexample.org
stackoverflow.com
python.org