
はじめに:リストだけじゃない!Pythonデータ管理の秘密兵器「set」とは?
Pythonで複数のデータをまとめて扱うとき、多くのビジネスパーソンはまず「リスト」を思い浮かべるでしょう。リストは非常に便利で、様々な場面で活躍します。しかし、「データの重複をなくしたい」「特定のデータが含まれているか素早くチェックしたい」といった特定の課題に直面したとき、リストだけでは処理が煩雑になったり、パフォーマンスが低下したりすることがあります。
そんなときに活躍するのが、Pythonの「set(セット)」型です。 setは日本語で「集合」を意味し、その名の通り数学の集合の概念に基づいたデータ型です。 setを使いこなすことで、データ処理のコードをよりシンプルに、そして高速にすることが可能になります。この記事では、プログラミング初心者であるビジネスパーソンの方々にも分かりやすく、setの基本から実務で役立つ応用例までを丁寧に解説していきます。

1. set型の基本:リストとの違いを理解しよう
set型を理解する上で最も重要なのは、リスト型との違いを明確に把握することです。主な違いは「順序の有無」と「重複の許容」の2点に集約されます。
| 特徴 | リスト (list) | セット (set) |
|---|---|---|
| 順序 | あり(追加した順に並ぶ) | なし(順序は保証されない) |
| 重複 | あり(同じ値を複数持てる) | なし(同じ値は自動的に1つにまとめられる) |
| 書き方 | [1, 2, 2, 3] |
{1, 2, 3} または set([1, 2, 2, 3]) |
setの作り方
setを作成する方法は主に2つあります。波括弧{}を使う方法と、set()関数を使う方法です。
# 波括弧{}を使って作成
fruits = {"apple", "banana", "orange", "apple"}
print(fruits)
# 出力結果: {'orange', 'banana', 'apple'} (順序は実行環境により異なる場合があります)
# set()関数を使ってリストから作成
numbers = set([1, 5, 2, 5, 1])
print(numbers)
# 出力結果: {1, 2, 5}どちらの例でも、重複していた"apple"や1, 5が自動的に削除され、ユニークな(一意な)要素だけが残っていることがわかります。
注意点:空のsetを作りたい場合、{}と書くと空の辞書(dict)型になってしまうため、必ずset()を使用してください。
要素の追加と削除
setは作成後でも要素を追加したり削除したりできます(これを「ミュータブル(変更可能)」と言います)。
- 追加:
add()メソッドを使います。 - 削除:
remove()メソッドを使います。 ただし、存在しない要素を削除しようとするとエラーになるため注意が必要です。
# 要素の追加
my_set = {1, 2, 3}
my_set.add(4)
print(my_set) # {1, 2, 3, 4}
# 要素の削除
my_set.remove(2)
print(my_set) # {1, 3, 4}2. setの強力な機能①:わずか1行でリストの重複を除去
実務で非常によくあるのが、「リストから重複しているデータを取り除きたい」というケースです。例えば、顧客リストから重複したメールアドレスを削除する、といった作業です。setを使えば、この処理が驚くほど簡単になります。
方法は、リストをsetに変換し、それを再びリストに戻すだけです。
# 重複を含む顧客IDのリスト
customer_ids = [101, 102, 103, 102, 104, 101, 105]
# setに変換して重複を除去
unique_ids_set = set(customer_ids)
print(unique_ids_set) # {101, 102, 103, 104, 105}
# 再びリストに変換
unique_ids_list = list(unique_ids_set)
print(unique_ids_list) # [101, 102, 103, 104, 105] (順序は元と異なる可能性があります)このように、list(set(元のリスト))という1行のコードで、簡単に重複のないリストを作成できます。 これはsetの最も便利で頻繁に使われるテクニックの一つです。
3. setの強力な機能②:集合演算で複雑なデータ抽出を瞬時に
setは数学の集合がベースになっているため、「和集合」や「積集合」といった集合演算が簡単に行えます。 これにより、複数のデータグループ間の関係性を調べるときに非常に役立ちます。
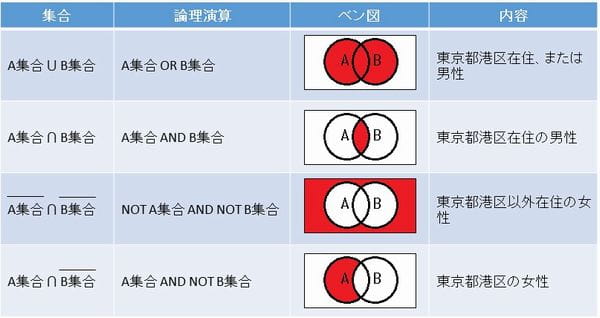
ここでは、2つの商品を購入した顧客グループを例に、代表的な集合演算を見ていきましょう。
# 商品Aの購入者ID
buyers_A = {1, 2, 3, 4, 5}
# 商品Bの購入者ID
buyers_B = {4, 5, 6, 7, 8}和集合 (union):どちらか一方でも購入した顧客
2つの集合の全ての要素を合わせたものです。「|」演算子またはunion()メソッドを使います。
# 和集合
all_buyers = buyers_A | buyers_B
print(all_buyers) # {1, 2, 3, 4, 5, 6, 7, 8}積集合 (intersection):両方とも購入した顧客
2つの集合に共通して含まれる要素だけを取り出したものです。「&」演算子またはintersection()メソッドを使います。
# 積集合
both_buyers = buyers_A & buyers_B
print(both_buyers) # {4, 5}差集合 (difference):商品Aは購入したが、商品Bは購入していない顧客
片方の集合から、もう片方の集合にも含まれる要素を取り除いたものです。「-」演算子またはdifference()メソッドを使います。
# 差集合 (Aにしかいない顧客)
a_only_buyers = buyers_A - buyers_B
print(a_only_buyers) # {1, 2, 3}4. なぜsetはこんなに速いのか?秘密は「ハッシュテーブル」
setのもう一つの大きな特徴は、特定の要素が含まれているかをチェックする処理(in演算)がリストに比べて圧倒的に速いことです。 データが数万、数百万件にもなると、その差は歴然とします。
この速さの秘密は、setが内部で「ハッシュテーブル」というデータ構造を使っている点にあります。
少し専門的になりますが、イメージで理解しましょう。
- リストの場合:リストで値を探すのは、名簿の最初から最後まで一人ずつ名前を読み上げて探すようなものです。データが増えるほど、探す時間も長くなります(線形探索)。
- setの場合:setは、各データ(要素)から「ハッシュ値」というユニークな番号を計算し、その番号に対応する棚にデータを格納します。値を探すときは、同じ計算で棚の番号を特定し、そこだけを直接見に行きます。 これにより、データ量がどれだけ増えても、探す時間はほとんど変わりません(定数時間O(1))。
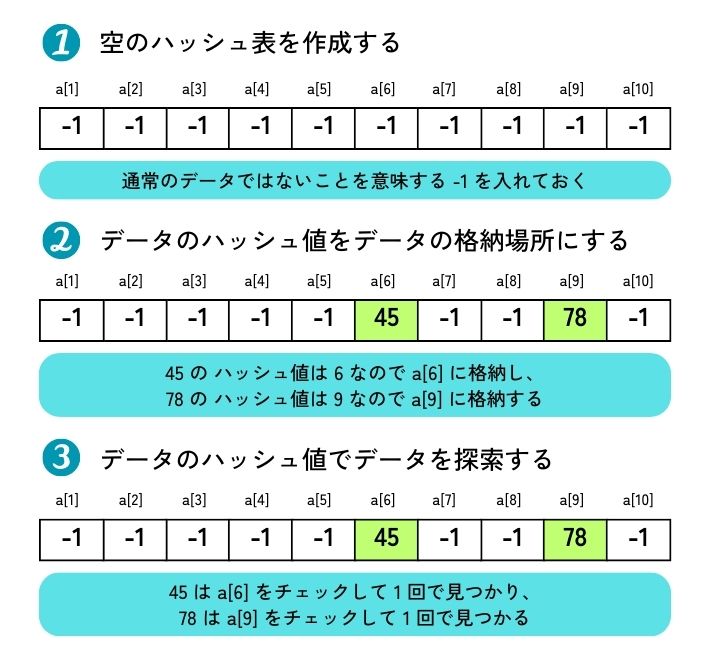
この仕組みのため、setは大量のデータの中から特定の要素を高速に検索したり、存在確認を行ったりするのに非常に適しているのです。
setに入れられるもの、入れられないもの(ハッシュ可能性)
ハッシュテーブルの仕組み上、setには「値が不変なもの」しか入れることができません。これを専門用語で「ハッシュ可能(hashable)」と言います。 数値や文字列、タプルなどは不変なのでsetに入れられますが、リストや辞書、他のsetのように後から中身を変更できるものは入れることができず、エラーになります。
5. 実務で役立つsetの応用例
これまで見てきた特徴を活かすと、ビジネスシーンの様々な場面でsetが役立ちます。
- データクレンジング:アンケート結果やログデータから、重複した回答やユーザーIDを削除し、ユニークなデータだけを抽出する。
- 高速なフィルタリング:NGワードのリストをsetにしておくことで、大量のテキストデータからNGワードを含むものを高速に検出する。
- 差分チェック:先月の顧客リストと今月の顧客リストをそれぞれsetにし、差集合を取ることで、新規顧客や解約顧客を簡単に見つけ出す。
- タグの分析:複数のブログ記事につけられたタグを分析し、共通して使われているタグ(積集合)や、全ての記事で使われているタグの総種類(和集合)を把握する。
まとめ:setを理解して賢いデータ管理を
今回は、Pythonのset型について、その基本的な特徴から実用的な使い方までを解説しました。
最後に重要なポイントを振り返りましょう。
- setは「順序がなく、重複を許さない」データ型です。
- リストの重複を削除したいときは、
list(set(リスト))が非常に便利です。 - 和集合(|)、積集合(&)、差集合(-)などの集合演算を使うと、複雑なデータ抽出がシンプルに書けます。
- 内部的にハッシュテーブルを使っているため、大量のデータに対する検索や存在確認が非常に高速です。
最初はリストとの使い分けに戸惑うかもしれませんが、「重複をなくしたい」「とにかく速く検索したい」というキーワードが出てきたら、ぜひsetの活用を検討してみてください。 setをマスターすれば、あなたのPythonプログラミングは一段と効率的で洗練されたものになるでしょう。
“`
Sources
help
it-biz.online
sejuku.net
rstone-jp.com
umateku.com
impl.co.jp
techmania.jp
popinsight.jp
nkmk.me
lighthouselab.co.jp
kikagaku.co.jp
github.io
javadrive.jp
qiita.com
qiita.com
techgym.jp
qiita.com
codecamp.jp
progadv.com