
Python型ヒント入門|typingとmypyでバグを未然に防ぐ“壊れにくい”コードの作り方
Pythonは柔軟で書きやすいプログラミング言語として、Web開発からデータ分析まで幅広い分野で人気です。しかし、その柔軟さゆえに、ある程度の規模のプログラムになると「この変数には何が入るんだっけ?」「この関数は何を返すのが正解?」といった問題に直面し、思わぬバグに時間を費やしてしまうことがあります。特に、複数人で開発を行うプロジェクトでは、このような認識のズレが大きな手戻りを生む原因にもなりかねません。
この記事では、そうした問題を解決し、コードの品質と開発効率を劇的に向上させる「型ヒント(Type Hints)」という機能について、プログラミング初心者や普段あまりコードに触れないビジネスパーソンにも分かるように、基礎から丁寧に解説します。さらに、型ヒントを強力にサポートするチェックツール「mypy」の使い方も紹介し、バグを未然に防ぐ「壊れにくいコード」の作り方を学んでいきましょう。

1. 型ヒントとは? なぜ重要なのか?
まず、「型」とは、データの種類のことです。例えば、「100」は数値(整数型)、「”こんにちは”」は文字列(文字列型)といった具合です。Pythonは、こうした「型」をあまり厳密に意識しなくてもプログラムが書ける「動的型付け言語」に分類されます。これは初心者にとって書きやすさというメリットがある一方で、プログラムを実行するまで型の間違いに気づきにくいというデメリットも抱えています。
そこで登場するのが「型ヒント」です。これは、変数や関数の引数・戻り値が「どのような型を想定しているか」をコード上に注釈として書き記しておく仕組みです。いわば、データに付ける「取扱説明書」のようなものだと考えてください。
型ヒントを導入する3つの大きなメリット
型ヒントは、Python 3.5から導入された比較的新しい機能ですが、現代のPython開発では欠かせないものとなりつつあります。その理由は、以下のような明確なメリットがあるからです。
| メリット | 説明 |
|---|---|
| コードの可読性向上 | 変数や関数がどのようなデータを扱うかが一目瞭然になり、他の人や未来の自分がコードを読んだときに、その意図を素早く正確に理解できます。 |
| バグの早期発見 | 後述する「mypy」などの静的解析ツールを使うことで、プログラムを実行する前に「型の不一致」といった潜在的なバグを発見できます。「実行時エラー」を大幅に減らせます。 |
| 開発効率の向上 | VSCodeやPyCharmといった高機能なエディタが型情報を解釈し、コードの自動補完(オートコンプリート)やエラーチェックをより正確に行ってくれます。これにより、タイピングミスが減り、開発スピードが向上します。 |
【重要】型ヒントはあくまで「ヒント」
一つ注意点として、型ヒントを書いても、Python自体がプログラム実行時にその型を強制するわけではありません。例えば、整数を入れると指定した変数に文字列を入れても、それだけではエラーになりません。型ヒントを活かすには、後で紹介する「静的型チェックツール」と組み合わせることが不可欠です。
2. 型ヒントの基本的な書き方 (typingモジュール)
それでは、実際にどのように型ヒントを書いていくのか見ていきましょう。Pythonでは、標準で用意されているtypingというモジュールを使って、様々な型を表現します。
変数と関数への基本的な型付け
まずは、変数と関数の基本的な型ヒントの書き方です。
変数への型ヒント:
変数名の後ろにコロン(:)を書き、その後に型名を記述します。
# 変数への型ヒントの例
age: int = 28 # age は int型 (整数)
name: str = "佐藤" # name は str型 (文字列)
height: float = 175.8 # height は float型 (小数点数)
is_active: bool = True # is_active は bool型 (True/False)
関数への型ヒント:
関数の引数には変数と同じように: 型名を、そして関数の戻り値(返り値)には、引数リストの閉じ括弧)の後ろにアロー(->)と型名を書きます。
# 関数の引数と戻り値への型ヒントの例
def create_greeting(name: str, age: int) -> str:
return f"こんにちは、{name}さん。あなたは{age}歳ですね。"
# この関数を使うとき
user_greeting = create_greeting("鈴木", 35)
print(user_greeting)
このように書くことで、create_greeting関数は「文字列(str)と整数(int)を引数として受け取り、文字列(str)を返す関数である」という仕様が明確になります。
リストや辞書など、コレクションの型ヒント
複数のデータをまとめて扱うリスト(list)や辞書(dict)にも、どのような型のデータが含まれるかを指定できます。これにはtypingモジュールのListやDictなどを使います。
from typing import List, Dict, Tuple, Set
# 整数のリスト
numbers: List[int] = [1, 5, 10, 15]
# キーが文字列で、値が整数の辞書
user_scores: Dict[str, int] = {"Yamada": 80, "Tanaka": 92}
# 複数の型を含むタプル(順番と型が固定されたリスト)
person_data: Tuple[str, int, float] = ("Sato", 40, 168.2)
# 文字列のセット(重複しない値の集まり)
tags: Set[str] = {"python", "development", "tutorial"}
# リストの中にリストが入っている二次元リストも表現可能
matrix: List[List[int]] = [
[1, 2, 3],
[4, 5, 6],
]
※ Python 3.9以降では、from typing import Listとしなくても、list[int]やdict[str, int]のように、標準の型をそのまま使えるようになりました。新しいバージョンのPythonを使っている場合は、こちらのほうが簡潔で推奨されます。
複数の型を許容したい場合 (Union, Optional)
時には、「整数または文字列」のように複数の型を受け入れたい場合や、「値がないかもしれない(None)」という状況を表現したい場合があります。
Union: いずれかの型
Union[型A, 型B]と書くことで、「型Aまたは型Bのどちらか」という意味になります。
from typing import Union
def display_id(user_id: Union[int, str]) -> None:
print(f"ユーザーID: {user_id}")
display_id(101) # OK
display_id("user-abc") # OK
※ Python 3.10以降では、int | strのようにパイプ演算子|で同じ意味をよりシンプルに書くことができます。
Optional: 値がないかもしれない場合
Optional[型A]と書くことで、「型AまたはNone」という意味になります。これは、デフォルト値がNoneである関数の引数などで非常によく使われます。
from typing import Optional
def find_user(user_id: int) -> Optional[str]:
if user_id == 1:
return "山田"
else:
return None # ユーザーが見つからない場合はNoneを返す
user_name = find_user(1)
if user_name is not None:
print(user_name.upper()) # user_nameがNoneでないことを保証して処理できる
Optionalを使うことで、「この関数は失敗してNoneを返す可能性がある」ということを明示でき、呼び出し側でNoneの場合の処理を忘れずに行うきっかけになります。
3. 辞書の構造を定義する「TypedDict」
ビジネスアプリケーション、特にWeb APIなどでデータをやり取りする際には、JSON形式(Pythonでは辞書として扱われることが多い)が頻繁に使われます。こうしたデータは「特定のキーが必ず存在する」「キーごとに値の型が決まっている」といった構造を持っています。
TypedDictは、このような構造を持つ辞書専用の型ヒントを作成する機能です。
from typing import TypedDict
# 「ユーザー情報」を表す辞書の型を定義
class UserProfile(TypedDict):
id: int
name: str
email: Optional[str] # emailはなくても良い (Optional)
def process_user(user: UserProfile) -> None:
print(f"ユーザー名: {user['name']} (ID: {user['id']})")
if user['email']:
print(f"Email: {user['email']}")
# UserProfile型の辞書を作成
user_data: UserProfile = {"id": 123, "name": "高橋", "email": "takahashi@example.com"}
process_user(user_data)
# キーが足りないと、後述のmypyがエラーを教えてくれる
invalid_data: UserProfile = {"id": 456} # 'name'キーが欠けている
# process_user(invalid_data) -> mypyでチェックするとエラーになる
TypedDictを使うことで、「user_dataという辞書には、必ずidとnameというキーがあり、それぞれの値は整数と文字列ですよ」というルールを明確にできます。これにより、キーの名前を打ち間違えたり、必須のデータを忘れたりするミスを実行前に発見できます。
4. 静的型チェックツール「mypy」でコードの健康診断をしよう
ここまで型ヒントの書き方を説明してきましたが、これらはあくまで「ヒント」であり、書いただけでは何の効果もありません。そこで登場するのが、静的型チェックツールmypyです。
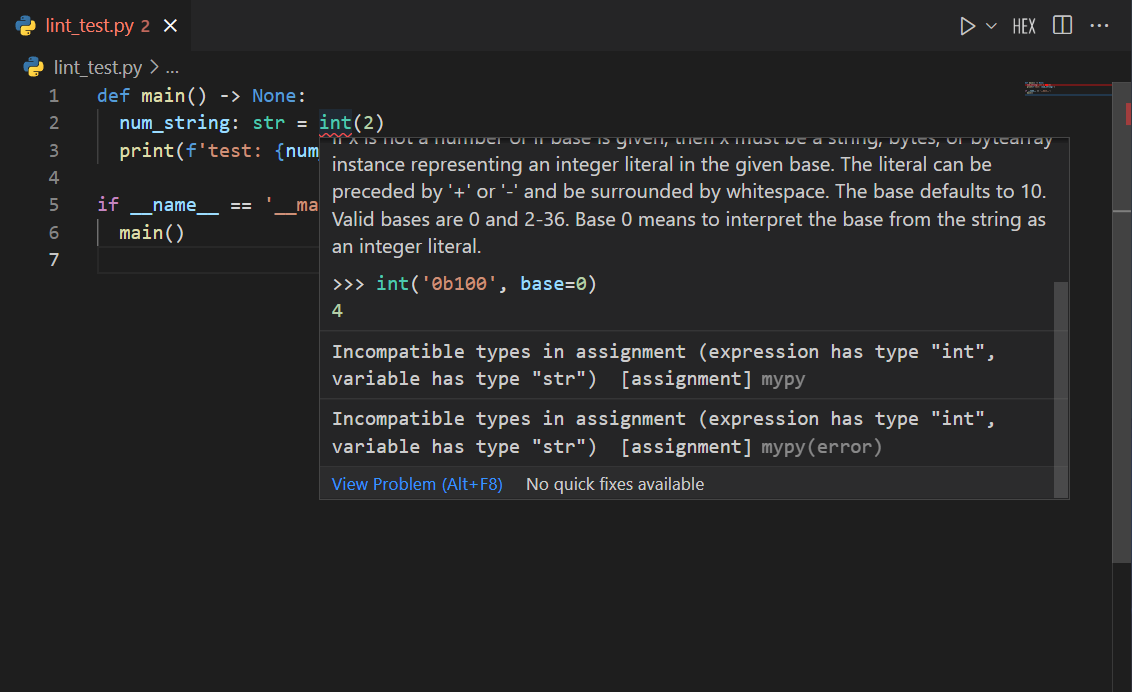
mypyは、書かれた型ヒントを元にコードを解析し、「型のルール違反」がないかをプログラム実行前にチェックしてくれるツールです。まるで、コードの健康診断を行ってくれるお医者さんのような存在です。
mypyのインストールと使い方
mypyはPythonの外部パッケージなので、pipコマンドで簡単にインストールできます。
pip install mypy
使い方は非常にシンプルで、チェックしたいPythonファイル名を指定してコマンドを実行するだけです。
mypy your_python_script.py
もしコードに型の問題がなければ、何も表示されずに終了します。問題が見つかった場合は、どのファイルの何行目にどんな問題があるのかを具体的に教えてくれます。
mypyが検出してくれるエラーの例:
# test_script.py
def add(a: int, b: int) -> int:
return a + b
# 間違った型の引数を渡している
result = add(5, "hello")
print(result)
このファイルに対してmypyを実行すると、次のようなエラーが表示されます。
$ mypy test_script.py
test_script.py:5: error: Argument 2 to "add" has incompatible type "str"; expected "int" [arg-type]
Found 1 error in 1 file (checked 1 source file)
「5行目のadd関数の第2引数の型が合わないよ。int(整数)を期待してたのにstr(文字列)が渡されてるよ」と、非常に分かりやすく指摘してくれます。これにより、プログラムを実行してエラーで落ちる前に、問題を修正することができるのです。
型ヒントとmypyを組み合わせる効果
- リファクタリングの安心感: コードの整理整頓(リファクタリング)を行う際に、修正によって意図しない型の変更が起きていないかをmypyがチェックしてくれるため、安心して大胆な改善ができます。
- ドキュメントとしての役割: 型ヒント自体が関数の仕様書のような役割を果たし、コードの意図を正確に伝えます。
- チーム開発の円滑化: メンバー間でデータの型に関する認識のズレがなくなり、コミュニケーションコストを削減し、コードの品質を一定に保つことができます。
5. 既存のコードに少しずつ導入するには? (段階的型付け)
「これだけメリットがあるならすぐにでも導入したいけど、既存の巨大なコード全部に型ヒントを書くのは大変そうだ…」と感じるかもしれません。ご安心ください。Pythonの型ヒントは「段階的型付け(Gradual Typing)」という考え方を採用しており、プロジェクト全体に一気に導入する必要はありません。
まずは、以下の様なアプローチで少しずつ始めるのがおすすめです。
- 新規コードから始める: これから新しく書く関数やクラスにだけ、型ヒントを付けるようにします。
- 重要な部分から始める: プロジェクトの中心となる関数や、バグが発生すると影響が大きいモジュールから優先的に型ヒントを追加していきます。
- 型チェックを一時的に無効にする: どうしても型ヒントを付けるのが難しい、あるいは外部ライブラリとの兼ね合いでエラーが解消できない箇所は、一時的にチェックを無効にすることも可能です。
特定の行のエラーを無視したい場合は、行末に# type: ignoreというコメントを追加します。これにより、mypyはその行をスキップしてくれるため、現実的な運用が可能になります。
まとめ
本記事では、Pythonの「型ヒント」と静的型チェックツール「mypy」について、その基本から実践的な使い方までを解説しました。最初は少し記述が増えて面倒に感じるかもしれませんが、得られるメリットは計り知れません。
- 型ヒントは、変数や関数が扱うデータの種類を明記する「取扱説明書」です。
- これにより、コードが読みやすくなり、エディタの開発支援機能も強化されます。
- mypyは、型ヒントを元にコードをチェックし、バグを未然に防ぐ「健康診断ツール」です。
- 型ヒントとmypyを組み合わせることで、コードの品質と信頼性が飛躍的に向上し、「壊れにくいコード」を実現できます。
- 導入は段階的に進めることが可能で、無理なくプロジェクトの安全性を高めていけます。
型ヒントを使いこなすことは、個人のスキルアップはもちろん、チーム全体の生産性を向上させるための強力な武器となります。ぜひ、今日からあなたのPythonコードに型ヒントを取り入れて、より快適で安全な開発を体験してみてください。
さらに深く学びたい方は、Pythonの公式ドキュメントやmypyの公式サイトを参照することをおすすめします。
“`