
Pythonにおける例外処理の基礎から実践まで【初心者向けガイド】
プログラムを作成していると、予期せぬエラーはつきものです。例えば、ユーザーが数値を入力すべきところに誤って文字を入力したり、読み込もうとしたファイルが存在しなかったり。こうした予期せぬ事態が発生した際にプログラムが突然停止してしまうと、ユーザーに不便をかけるだけでなく、重要なデータが失われる原因にもなりかねません。そこで重要になるのが「例外処理」です。
例外処理とは、エラーが発生したことを検知し、プログラムが強制終了するのを防ぎ、代わりの処理を実行するための仕組みです。いわば、プログラムにおける「転ばぬ先の杖」や「問題発生時の対応マニュアル」のようなものです。この例外処理を適切に実装することで、プログラムはより堅牢で、利用者にとって親切なものになります。
この記事では、プログラミング初心者や非専門家のビジネスパーソンの方でも理解できるよう、Pythonにおける例外処理の基本から、実務で役立つ設計パターン、そして知っておくべきベストプラクティスまでを、専門用語を避けつつ丁寧に解説していきます。
1. Python例外処理の基本構文
まずは、Pythonで例外処理を記述するための基本的な構文を見ていきましょう。主にtry, except, else, finally, raiseという5つのキーワードが中心となります。これらの役割を理解することが、例外処理マスターへの第一歩です。
try と except:エラーを捕まえる基本
例外処理の最も基本的な形が、tryブロックとexceptブロックの組み合わせです。
- tryブロック: エラーが発生する可能性のあるコードをこの中に記述します。いわば「お試し実行」のブロックです。
- exceptブロック:
tryブロック内でエラーが発生した場合に実行される処理を記述します。エラー発生時の「緊急対応」マニュアルです。
例えば、プログラムでよくある「ゼロ除算」(数値を0で割ろうとすること)のエラーを処理するコードを見てみましょう。
try:
# ユーザーからの入力を想定
a = 10
b = 0
result = a / b # ここでエラー(ZeroDivisionError)が発生
print(f"計算結果: {result}")
except ZeroDivisionError:
# ZeroDivisionErrorという種類のエラーが発生した場合の処理
print("エラー: ゼロで割ることはできません。")
# 出力結果:
# エラー: ゼロで割ることはできません。
このコードでは、tryブロック内で10 / 0という計算が実行され、ZeroDivisionErrorというエラーが発生します。 すると、Pythonは直ちにtryブロックの残りの処理(この場合はprint文)を中断し、対応するexcept ZeroDivisionErrorブロックに処理を移します。 その結果、エラーメッセージが表示され、プログラムは強制終了することなく処理を続けることができます。
exceptブロックは、特定のエラー(例: ZeroDivisionError, FileNotFoundError)を指定して捕捉するのが基本です。 複数の種類のエラーに対応したい場合は、exceptブロックを複数並べたり、except (TypeError, ValueError):のようにタプルでまとめたりすることも可能です。
注意点: except: のようにエラーの種類を省略すると、プログラムを中断させるためのキーボード操作(Ctrl+C)なども含め、あらゆるエラーを捕捉してしまい、意図しない挙動の原因となるため避けるべきです。
else節:エラーが起きなかった場合の処理
else節は、tryブロック内で例外が発生しなかった場合にのみ実行される処理を記述します。 これにより、「成功時の処理」をエラー処理の構文から明確に分離でき、コードが読みやすくなります。
try:
# 存在しないかもしれないファイルを開いてみる
f = open("data.txt", "r")
except FileNotFoundError:
print("エラー: ファイルが見つかりません。")
else:
# ファイルが無事開けた場合のみ実行される
print("ファイルを開くのに成功しました。")
data = f.read()
print(f"ファイル内容: {data}")
f.close()
この例では、”data.txt”というファイルが存在すればelseブロックが実行され、ファイル内容が表示されます。もしファイルが存在しなければexceptブロックが実行されます。 tryブロックの中身を「エラーが起こりうる最小限の処理」(この場合はopen関数)に限定できるのがelseを使うメリットです。
finally節:後片付けのための最終処理
finally節に記述されたコードは、例外の発生有無にかかわらず、必ず最後に実行されます。 プログラムがどのような経路をたどっても、最後に必ず行いたい「後片付け」処理(ファイルやネットワーク接続を閉じる、など)を記述するのに最適です。
f = None # あらかじめ変数を定義しておく
try:
f = open("data.txt", "r")
# ... ファイルに対する何らかの処理 ...
# わざとエラーを起こしてみる
result = 10 / 0
except FileNotFoundError:
print("ファイルが見つかりません。")
except ZeroDivisionError:
print("計算エラーが発生しました。")
finally:
# エラーがあってもなくても、ファイルが開かれていれば必ず閉じる
if f:
f.close()
print("後片付け処理が完了しました。")
このコードでは、ファイルが見つからなくても、計算エラーが起きても、あるいは正常に処理が完了しても、最後に必ずfinallyブロックが実行され、ファイルが閉じられることが保証されます。 これにより、リソースの解放漏れといったバグを防ぐことができます。
raise文:意図的に例外を発生させる
これまでは発生した例外を「捕まえる」側でしたが、raise文を使うと、逆にプログラマが意図的に例外を発生させることができます。 これは、関数の引数が不正である場合など、プログラムの仕様上の「エラー」を通知するために使われます。
def set_age(age):
if not isinstance(age, int) or age 0:
# 年齢として不正な値が渡されたら、エラーを発生させる
raise ValueError("年齢は0以上の整数でなければなりません。")
print(f"年齢を{age}歳に設定しました。")
try:
set_age(-5)
except ValueError as e:
# raiseで発生させたエラーをexceptで捕まえる
print(f"エラーが発生しました: {e}")
# 出力結果:
# エラーが発生しました: 年齢は0以上の整数でなければなりません。
このように、特定の条件を満たさない場合にraiseを使ってエラーを発生させることで、プログラムが不正な状態のまま処理を続行するのを防ぎ、問題の早期発見に繋げることができます。
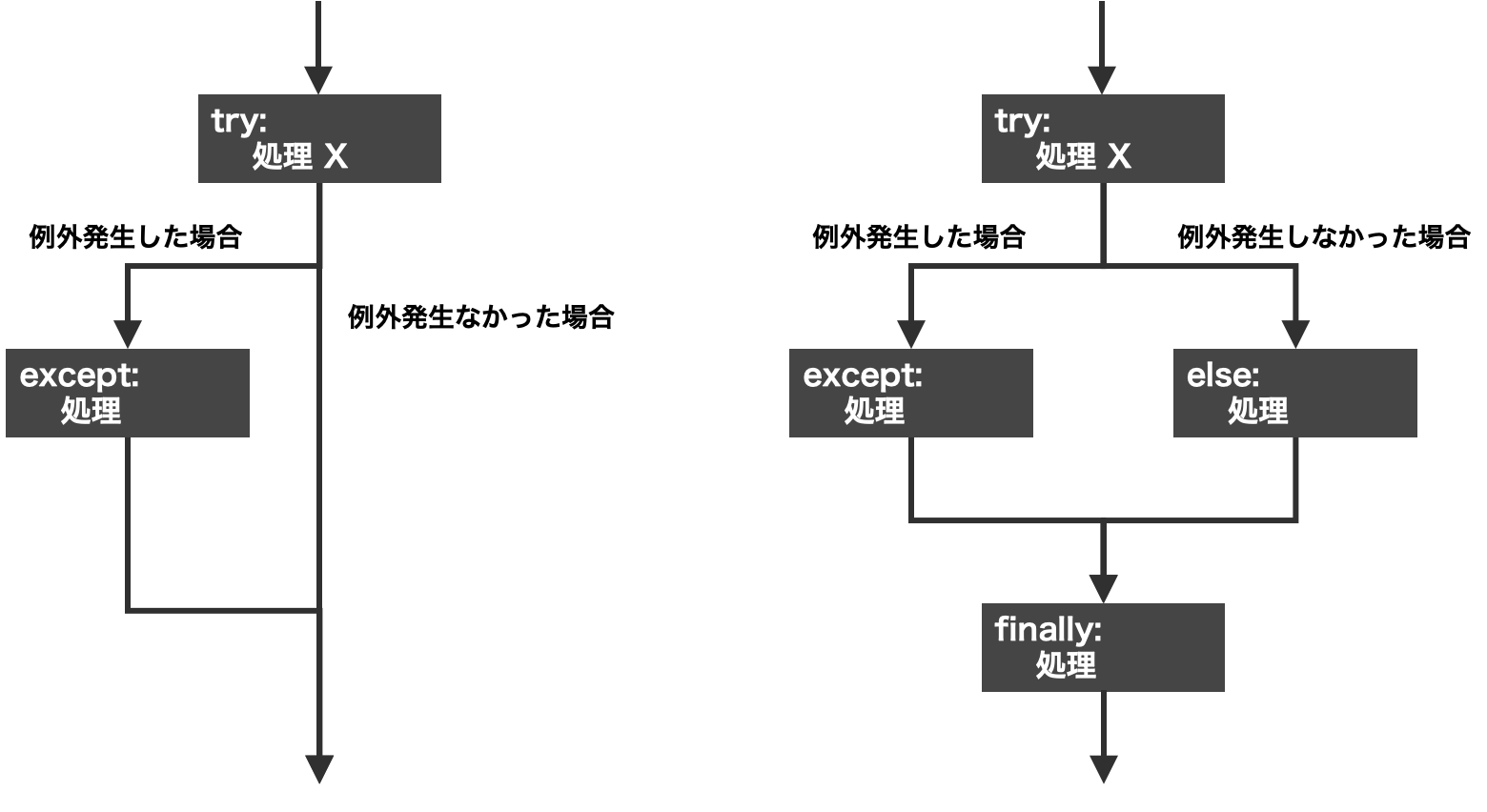
図: try/except/else/finallyの基本的な処理フロー
2. よくある例外処理の失敗例・落とし穴
例外処理は強力なツールですが、使い方を誤るとかえってバグの原因を隠蔽してしまうことがあります。ここでは、初心者が陥りがちな典型的な失敗例(アンチパターン)を見ていきましょう。

失敗例1:例外を握りつぶす(無視する)
最もやってはいけないのが、エラーが発生したにもかかわらず、何もせず処理を続行させてしまうことです。これは「例外を握りつぶす」と呼ばれます。
# 悪い例
try:
# 何か重要な処理
process_data()
except Exception:
pass # 何もせず、エラーを無視する
このコードでは、process_data関数でどんなエラーが起きても、passによって完全に無視されます。 これでは、プログラムは一見正常に動いているように見えても、裏では問題が発生しており、後々深刻なデータ不整合や原因不明の不具合を引き起こす可能性があります。 エラーは決して無視せず、最低でもログに記録するべきです。
失敗例2:捕捉範囲が広すぎる
except Exception:や、エラーの種類を省略したexcept:のように、非常に広い範囲の例外をまとめて捕捉するのも問題です。 これでは、本来想定していなかった種類のエラーまで捕捉してしまい、プログラムのバグを隠してしまう恐れがあります。
例えば、ファイルが見つからないエラー(FileNotFoundError)を想定していたのに、except Exception:で捕捉してしまうと、タイプミスによる文法エラー(TypeError)など、全く別の問題まで同じ処理で扱ってしまいます。可能な限り、捕捉する例外は具体的に指定するべきです。
失敗例3:エラーの原因を追跡できなくする
エラーが発生した際には、「どこで、なぜ」エラーが起きたかを示す「スタックトレース(traceback)」という情報が出力されます。これはバグ修正のための非常に重要な手がかりですが、不適切な例外処理によってこの情報が失われてしまうことがあります。
# あまり良くない例
import traceback
try:
result = 10 / 0
except Exception as e:
# エラーメッセージしか表示されない
print(f"エラー: {e}")
# 適切にスタックトレースを出力するには、以下のようにする
# print(traceback.format_exc())
エラーメッセージeだけを表示すると、何行目でエラーが起きたかといった詳細が分かりません。 デバッグ時には、後述するloggingモジュールを使うか、tracebackモジュールを使って、必ずスタックトレースを記録するようにしましょう。
失敗例4:安易にprintで済ませてしまう
開発中に一時的にprint文でエラーを確認するのは便利ですが、本番のアプリケーションでこれを行うのは不適切です。 Webアプリケーションやサーバー上で動くプログラムでは、コンソールに出力されたprintメッセージを誰も見ることができません。また、ログファイルとして記録されないため、後からエラーを分析することも困難です。エラー情報は、次に紹介するloggingモジュールを使って、ファイルなどに恒久的に記録するのが基本です。
3. 実務で使える例外処理の設計パターン
基本的な構文を理解したら、次はより実践的な設計パターンを学びましょう。実際の業務アプリケーションでは、エラーをどのように整理し、扱うかがシステムの品質を大きく左右します。
ユーザー向けメッセージと開発者向けログの分離
エラーが発生した際、その情報を誰にどのように見せるかは非常に重要です。基本原則は、「エンドユーザー」と「開発者」で提供する情報を完全に分けることです。
- ユーザー向けメッセージ: ユーザーには、技術的な詳細を見せるべきではありません。 「申し訳ありません、予期せぬエラーが発生しました。時間をおいて再度お試しください。」といったシンプルで分かりやすいメッセージや、「入力形式が正しくありません。」のように次にとるべき行動を示すメッセージを表示します。
- 開発者向けログ/通知: 一方、開発者やシステム管理者向けには、問題解決に必要な全ての情報を記録します。これには、詳細なスタックトレース、エラー発生時のデータ、ユーザーIDなどが含まれます。 この情報は、ファイルログやエラー監視システムに送信するのが一般的です。
この分離により、ユーザー体験を損なうことなく、迅速なバグ修正に必要な情報を確保できます。
独自例外(カスタム例外)の定義と活用
Pythonに組み込まれているValueErrorやTypeErrorだけでなく、アプリケーション固有のエラー状況を表すために、独自の例外クラスを定義することがよくあります。
# 独自の例外クラスを定義
class InsufficientStockError(Exception):
"""在庫不足を表すエラー"""
pass
def place_order(item_id, quantity):
stock = get_stock(item_id)
if stock quantity:
# 在庫が不足している場合、独自例外を発生させる
raise InsufficientStockError(f"{item_id}の在庫が不足しています。")
# ... 注文処理 ...
try:
place_order("APPLE-01", 10)
except InsufficientStockError as e:
print(f"注文処理に失敗しました: {e}")
このように、「在庫不足」といったビジネスルール上のエラーを独自の例外として定義することで、コードの意図が明確になり、エラーハンドリングがしやすくなります。 慣習として、例外クラス名は「Error」で終わるように命名します。
層ごとのエラーハンドリングの責務分離
大規模なシステムは、多くの場合「プレゼンテーション層(UI)」「ビジネスロジック層」「データアクセス層」といった階層構造(レイヤードアーキテクチャ)で作られます。このような構造では、どの層がどのエラーに責任を持つかを明確にすることが重要です。
| 層 | 主な役割とエラーハンドリング |
|---|---|
| 上位層(UI層) | 最終的な砦として全てのエラーを捕捉します。 ユーザーにエラーメッセージを表示し、詳細をログに記録します。 |
| 中間層(ビジネスロジック層) | 下位層からのエラーを捕捉し、よりビジネス的な文脈を持つ独自例外に変換して上位層に投げ直すことがあります(例:データベースエラーを「顧客情報の取得失敗」エラーに変換)。 |
| 下位層(データアクセス層) | データベース接続エラーなど、技術的なエラーを発生させます。 ここでは、デバッグに役立つ詳細な情報を含んだ例外を投げることに専念します。 |
このように責務を分離することで、各層は自身の役割に集中でき、見通しの良いエラー処理が実現できます。 重要なのは、対処できないエラーはその場で握りつぶさず、適切に対応できる上位の層に任せるという原則です。
ログ出力のベストプラクティス(loggingモジュールの活用)
Pythonには、標準で高機能なログ出力ライブラリloggingが用意されています。実務では、エラー記録にprintではなく、このモジュールを使うのが鉄則です。
import logging
# ログの設定(ファイルに出力、フォーマット指定など)
logging.basicConfig(level=logging.ERROR,
filename='app.log',
format='%(asctime)s - %(levelname)s - %(message)s')
try:
result = 10 / 0
except ZeroDivisionError:
# スタックトレースを含めてERRORレベルでログを記録
logging.exception("計算中にエラーが発生しました")
logging.exception()を使うと、エラーメッセージと共に詳細なスタックトレースが自動で記録されるため、デバッグに非常に役立ちます。 記録されたログは、後から問題の原因を分析するための貴重な資料となります。
4. Python例外処理に関するベストプラクティス
最後に、より良い例外処理コードを書くための、Pythonコミュニティで広く知られているベストプラクティスや考え方を紹介します。
- エラーは決して黙って通してはならない (Errors should never pass silently.)
これはPythonの設計哲学 “The Zen of Python” の一節です。 エラーを無視することは、問題の先送りにしかならないという教えです。 - tryブロックはできるだけ短く保つ
tryブロックには、エラーが発生する可能性のあるコードだけを記述し、不必要に広げないようにします。 これにより、意図しないエラーを捕捉してしまうことを防げます。 - EAFP: 許可を求めるより許しを乞う
“Easier to Ask for Forgiveness than Permission” の略で、「事前にチェックするより、まず実行してみて、エラーになったら対処する」というPythonで好まれるスタイルです。# EAFPスタイル (Python的) try: process_file("data.csv") except FileNotFoundError: print("ファイルが存在しませんでした。") - リソース管理は
with文を使う
ファイルやネットワーク接続など、後片付けが必要なリソースを扱う際は、try...finallyを手で書くよりもwith文を使うのが一般的です。withブロックを抜ける際に自動で後片付け処理が呼ばれるため、コードが簡潔になり、解放漏れも防げます。 - 例外チェーンを活用する
あるエラーを受けて別のエラーを発生させる場合、raise NewError from original_errorという構文を使うと、元のエラー情報を引き継ぐことができます。 これにより、エラーの根本原因を追いやすくなります。
まとめ
本記事では、Pythonにおける例外処理の基本から、実務での応用、そしてベストプラクティスに至るまでを解説しました。例外処理は、単にプログラムのクラッシュを防ぐだけでなく、システムの信頼性と保守性を高めるための重要な技術です。
最初は少し複雑に感じるかもしれませんが、以下のポイントを意識することから始めてみてください。
- エラーは無視せず、必ず何らかの形で対処する(最低でもログに記録する)。
exceptで捕捉するエラーは、できるだけ具体的な種類に限定する。- ユーザーに見せるメッセージと、開発者が分析するためのログは明確に分ける。
- ファイルなどの後片付けが必要な処理では、
finallyやwith文を積極的に活用する。
適切なエラーハンドリングを身につけることで、あなたの書くプログラムは、予期せぬ事態にも優雅に対応できる、よりプロフェッショナルなものへと進化するでしょう。
“`
—
### 納品用HTML(citationタグ除去済み)
“`html
Pythonにおける例外処理の基礎から実践まで【初心者向けガイド】
プログラムを作成していると、予期せぬエラーはつきものです。例えば、ユーザーが数値を入力すべきところに誤って文字を入力したり、読み込もうとしたファイルが存在しなかったり。こうした予期せぬ事態が発生した際にプログラムが突然停止してしまうと、ユーザーに不便をかけるだけでなく、重要なデータが失われる原因にもなりかねません。そこで重要になるのが「例外処理」です。
例外処理とは、エラーが発生したことを検知し、プログラムが強制終了するのを防ぎ、代わりの処理を実行するための仕組みです。いわば、プログラムにおける「転ばぬ先の杖」や「問題発生時の対応マニュアル」のようなものです。この例外処理を適切に実装することで、プログラムはより堅牢で、利用者にとって親切なものになります。
この記事では、プログラミング初心者や非専門家のビジネスパーソンの方でも理解できるよう、Pythonにおける例外処理の基本から、実務で役立つ設計パターン、そして知っておくべきベストプラクティスまでを、専門用語を避けつつ丁寧に解説していきます。
1. Python例外処理の基本構文
まずは、Pythonで例外処理を記述するための基本的な構文を見ていきましょう。主にtry, except, else, finally, raiseという5つのキーワードが中心となります。これらの役割を理解することが、例外処理マスターへの第一歩です。
try と except:エラーを捕まえる基本
例外処理の最も基本的な形が、tryブロックとexceptブロックの組み合わせです。
- tryブロック: エラーが発生する可能性のあるコードをこの中に記述します。いわば「お試し実行」のブロックです。
- exceptブロック:
tryブロック内でエラーが発生した場合に実行される処理を記述します。エラー発生時の「緊急対応」マニュアルです。
例えば、プログラムでよくある「ゼロ除算」(数値を0で割ろうとすること)のエラーを処理するコードを見てみましょう。
try:
# ユーザーからの入力を想定
a = 10
b = 0
result = a / b # ここでエラー(ZeroDivisionError)が発生
print(f"計算結果: {result}")
except ZeroDivisionError:
# ZeroDivisionErrorという種類のエラーが発生した場合の処理
print("エラー: ゼロで割ることはできません。")
# 出力結果:
# エラー: ゼロで割ることはできません。
このコードでは、tryブロック内で10 / 0という計算が実行され、ZeroDivisionErrorというエラーが発生します。 すると、Pythonは直ちにtryブロックの残りの処理(この場合はprint文)を中断し、対応するexcept ZeroDivisionErrorブロックに処理を移します。 その結果、エラーメッセージが表示され、プログラムは強制終了することなく処理を続けることができます。
exceptブロックは、特定のエラー(例: ZeroDivisionError, FileNotFoundError)を指定して捕捉するのが基本です。 複数の種類のエラーに対応したい場合は、exceptブロックを複数並べたり、except (TypeError, ValueError):のようにタプルでまとめたりすることも可能です。
注意点: except: のようにエラーの種類を省略すると、プログラムを中断させるためのキーボード操作(Ctrl+C)なども含め、あらゆるエラーを捕捉してしまい、意図しない挙動の原因となるため避けるべきです。
else節:エラーが起きなかった場合の処理
else節は、tryブロック内で例外が発生しなかった場合にのみ実行される処理を記述します。 これにより、「成功時の処理」をエラー処理の構文から明確に分離でき、コードが読みやすくなります。
try:
# 存在しないかもしれないファイルを開いてみる
f = open("data.txt", "r")
except FileNotFoundError:
print("エラー: ファイルが見つかりません。")
else:
# ファイルが無事開けた場合のみ実行される
print("ファイルを開くのに成功しました。")
data = f.read()
print(f"ファイル内容: {data}")
f.close()
この例では、”data.txt”というファイルが存在すればelseブロックが実行され、ファイル内容が表示されます。もしファイルが存在しなければexceptブロックが実行されます。 tryブロックの中身を「エラーが起こりうる最小限の処理」(この場合はopen関数)に限定できるのがelseを使うメリットです。
finally節:後片付けのための最終処理
finally節に記述されたコードは、例外の発生有無にかかわらず、必ず最後に実行されます。 プログラムがどのような経路をたどっても、最後に必ず行いたい「後片付け」処理(ファイルやネットワーク接続を閉じる、など)を記述するのに最適です。
f = None # あらかじめ変数を定義しておく
try:
f = open("data.txt", "r")
# ... ファイルに対する何らかの処理 ...
# わざとエラーを起こしてみる
result = 10 / 0
except FileNotFoundError:
print("ファイルが見つかりません。")
except ZeroDivisionError:
print("計算エラーが発生しました。")
finally:
# エラーがあってもなくても、ファイルが開かれていれば必ず閉じる
if f:
f.close()
print("後片付け処理が完了しました。")
このコードでは、ファイルが見つからなくても、計算エラーが起きても、あるいは正常に処理が完了しても、最後に必ずfinallyブロックが実行され、ファイルが閉じられることが保証されます。 これにより、リソースの解放漏れといったバグを防ぐことができます。
raise文:意図的に例外を発生させる
これまでは発生した例外を「捕まえる」側でしたが、raise文を使うと、逆にプログラマが意図的に例外を発生させることができます。 これは、関数の引数が不正である場合など、プログラムの仕様上の「エラー」を通知するために使われます。
def set_age(age):
if not isinstance(age, int) or age 0:
# 年齢として不正な値が渡されたら、エラーを発生させる
raise ValueError("年齢は0以上の整数でなければなりません。")
print(f"年齢を{age}歳に設定しました。")
try:
set_age(-5)
except ValueError as e:
# raiseで発生させたエラーをexceptで捕まえる
print(f"エラーが発生しました: {e}")
# 出力結果:
# エラーが発生しました: 年齢は0以上の整数でなければなりません。
このように、特定の条件を満たさない場合にraiseを使ってエラーを発生させることで、プログラムが不正な状態のまま処理を続行するのを防ぎ、問題の早期発見に繋げることができます。
図: try/except/else/finallyの基本的な処理フロー
2. よくある例外処理の失敗例・落とし穴
例外処理は強力なツールですが、使い方を誤るとかえってバグの原因を隠蔽してしまうことがあります。ここでは、初心者が陥りがちな典型的な失敗例(アンチパターン)を見ていきましょう。
失敗例1:例外を握りつぶす(無視する)
最もやってはいけないのが、エラーが発生したにもかかわらず、何もせず処理を続行させてしまうことです。これは「例外を握りつぶす」と呼ばれます。
# 悪い例
try:
# 何か重要な処理
process_data()
except Exception:
pass # 何もせず、エラーを無視する
このコードでは、process_data関数でどんなエラーが起きても、passによって完全に無視されます。 これでは、プログラムは一見正常に動いているように見えても、裏では問題が発生しており、後々深刻なデータ不整合や原因不明の不具合を引き起こす可能性があります。 エラーは決して無視せず、最低でもログに記録するべきです。
失敗例2:捕捉範囲が広すぎる
except Exception:や、エラーの種類を省略したexcept:のように、非常に広い範囲の例外をまとめて捕捉するのも問題です。 これでは、本来想定していなかった種類のエラーまで捕捉してしまい、プログラムのバグを隠してしまう恐れがあります。
例えば、ファイルが見つからないエラー(FileNotFoundError)を想定していたのに、except Exception:で捕捉してしまうと、タイプミスによる文法エラー(TypeError)など、全く別の問題まで同じ処理で扱ってしまいます。可能な限り、捕捉する例外は具体的に指定するべきです。
失敗例3:エラーの原因を追跡できなくする
エラーが発生した際には、「どこで、なぜ」エラーが起きたかを示す「スタックトレース(traceback)」という情報が出力されます。これはバグ修正のための非常に重要な手がかりですが、不適切な例外処理によってこの情報が失われてしまうことがあります。
# あまり良くない例
import traceback
try:
result = 10 / 0
except Exception as e:
# エラーメッセージしか表示されない
print(f"エラー: {e}")
# 適切にスタックトレースを出力するには、以下のようにする
# print(traceback.format_exc())
エラーメッセージeだけを表示すると、何行目でエラーが起きたかといった詳細が分かりません。 デバッグ時には、後述するloggingモジュールを使うか、tracebackモジュールを使って、必ずスタックトレースを記録するようにしましょう。
失敗例4:安易にprintで済ませてしまう
開発中に一時的にprint文でエラーを確認するのは便利ですが、本番のアプリケーションでこれを行うのは不適切です。 Webアプリケーションやサーバー上で動くプログラムでは、コンソールに出力されたprintメッセージを誰も見ることができません。また、ログファイルとして記録されないため、後からエラーを分析することも困難です。エラー情報は、次に紹介するloggingモジュールを使って、ファイルなどに恒久的に記録するのが基本です。
3. 実務で使える例外処理の設計パターン
基本的な構文を理解したら、次はより実践的な設計パターンを学びましょう。実際の業務アプリケーションでは、エラーをどのように整理し、扱うかがシステムの品質を大きく左右します。
ユーザー向けメッセージと開発者向けログの分離
エラーが発生した際、その情報を誰にどのように見せるかは非常に重要です。基本原則は、「エンドユーザー」と「開発者」で提供する情報を完全に分けることです。
- ユーザー向けメッセージ: ユーザーには、技術的な詳細を見せるべきではありません。 「申し訳ありません、予期せぬエラーが発生しました。時間をおいて再度お試しください。」といったシンプルで分かりやすいメッセージや、「入力形式が正しくありません。」のように次にとるべき行動を示すメッセージを表示します。
- 開発者向けログ/通知: 一方、開発者やシステム管理者向けには、問題解決に必要な全ての情報を記録します。これには、詳細なスタックトレース、エラー発生時のデータ、ユーザーIDなどが含まれます。 この情報は、ファイルログやエラー監視システムに送信するのが一般的です。
この分離により、ユーザー体験を損なうことなく、迅速なバグ修正に必要な情報を確保できます。
独自例外(カスタム例外)の定義と活用
Pythonに組み込まれているValueErrorやTypeErrorだけでなく、アプリケーション固有のエラー状況を表すために、独自の例外クラスを定義することがよくあります。
# 独自の例外クラスを定義
class InsufficientStockError(Exception):
"""在庫不足を表すエラー"""
pass
def place_order(item_id, quantity):
stock = get_stock(item_id)
if stock quantity:
# 在庫が不足している場合、独自例外を発生させる
raise InsufficientStockError(f"{item_id}の在庫が不足しています。")
# ... 注文処理 ...
try:
place_order("APPLE-01", 10)
except InsufficientStockError as e:
print(f"注文処理に失敗しました: {e}")
このように、「在庫不足」といったビジネスルール上のエラーを独自の例外として定義することで、コードの意図が明確になり、エラーハンドリングがしやすくなります。 慣習として、例外クラス名は「Error」で終わるように命名します。
層ごとのエラーハンドリングの責務分離
大規模なシステムは、多くの場合「プレゼンテーション層(UI)」「ビジネスロジック層」「データアクセス層」といった階層構造(レイヤードアーキテクチャ)で作られます。このような構造では、どの層がどのエラーに責任を持つかを明確にすることが重要です。
| 層 | 主な役割とエラーハンドリング |
|---|---|
| 上位層(UI層) | 最終的な砦として全てのエラーを捕捉します。 ユーザーにエラーメッセージを表示し、詳細をログに記録します。 |
| 中間層(ビジネスロジック層) | 下位層からのエラーを捕捉し、よりビジネス的な文脈を持つ独自例外に変換して上位層に投げ直すことがあります(例:データベースエラーを「顧客情報の取得失敗」エラーに変換)。 |
| 下位層(データアクセス層) | データベース接続エラーなど、技術的なエラーを発生させます。 ここでは、デバッグに役立つ詳細な情報を含んだ例外を投げることに専念します。 |
このように責務を分離することで、各層は自身の役割に集中でき、見通しの良いエラー処理が実現できます。 重要なのは、対処できないエラーはその場で握りつぶさず、適切に対応できる上位の層に任せるという原則です。
ログ出力のベストプラクティス(loggingモジュールの活用)
Pythonには、標準で高機能なログ出力ライブラリloggingが用意されています。実務では、エラー記録にprintではなく、このモジュールを使うのが鉄則です。
import logging
# ログの設定(ファイルに出力、フォーマット指定など)
logging.basicConfig(level=logging.ERROR,
filename='app.log',
format='%(asctime)s - %(levelname)s - %(message)s')
try:
result = 10 / 0
except ZeroDivisionError:
# スタックトレースを含めてERRORレベルでログを記録
logging.exception("計算中にエラーが発生しました")
logging.exception()を使うと、エラーメッセージと共に詳細なスタックトレースが自動で記録されるため、デバッグに非常に役立ちます。 記録されたログは、後から問題の原因を分析するための貴重な資料となります。
4. Python例外処理に関するベストプラクティス
最後に、より良い例外処理コードを書くための、Pythonコミュニティで広く知られているベストプラクティスや考え方を紹介します。
- エラーは決して黙って通してはならない (Errors should never pass silently.)
これはPythonの設計哲学 “The Zen of Python” の一節です。 エラーを無視することは、問題の先送りにしかならないという教えです。 - tryブロックはできるだけ短く保つ
tryブロックには、エラーが発生する可能性のあるコードだけを記述し、不必要に広げないようにします。 これにより、意図しないエラーを捕捉してしまうことを防げます。 - EAFP: 許可を求めるより許しを乞う
“Easier to Ask for Forgiveness than Permission” の略で、「事前にチェックするより、まず実行してみて、エラーになったら対処する」というPythonで好まれるスタイルです。# EAFPスタイル (Python的) try: process_file("data.csv") except FileNotFoundError: print("ファイルが存在しませんでした。") - リソース管理は
with文を使う
ファイルやネットワーク接続など、後片付けが必要なリソースを扱う際は、try...finallyを手で書くよりもwith文を使うのが一般的です。withブロックを抜ける際に自動で後片付け処理が呼ばれるため、コードが簡潔になり、解放漏れも防げます。 - 例外チェーンを活用する
あるエラーを受けて別のエラーを発生させる場合、raise NewError from original_errorという構文を使うと、元のエラー情報を引き継ぐことができます。 これにより、エラーの根本原因を追いやすくなります。
まとめ
本記事では、Pythonにおける例外処理の基本から、実務での応用、そしてベストプラクティスに至るまでを解説しました。例外処理は、単にプログラムのクラッシュを防ぐだけでなく、システムの信頼性と保守性を高めるための重要な技術です。
最初は少し複雑に感じるかもしれませんが、以下のポイントを意識することから始めてみてください。
- エラーは無視せず、必ず何らかの形で対処する(最低でもログに記録する)。
exceptで捕捉するエラーは、できるだけ具体的な種類に限定する。- ユーザーに見せるメッセージと、開発者が分析するためのログは明確に分ける。
- ファイルなどの後片付けが必要な処理では、
finallyやwith文を積極的に活用する。
適切なエラーハンドリングを身につけることで、あなたの書くプログラムは、予期せぬ事態にも優雅に対応できる、よりプロフェッショナルなものへと進化するでしょう。